Importance of Unsupervised Learning
Unsupervised Learning is another major approach within Machine Learning, notable for its ability to discover patterns in data without the need for labeled examples. Its importance has grown as organizations accumulate vast amounts of unstructured information such as images, text, and sensor readings. By uncovering hidden structures, Unsupervised Learning helps reveal insights that might otherwise remain invisible.
For social innovation and international development, this matters because many communities and programs lack the resources to create large labeled datasets. Unsupervised methods allow organizations to work with raw data directly, finding natural groupings or anomalies that can guide better decisions. This approach supports discovery in contexts where knowledge is incomplete, resources are scarce, and new relationships need to be surfaced.
Definition and Key Features
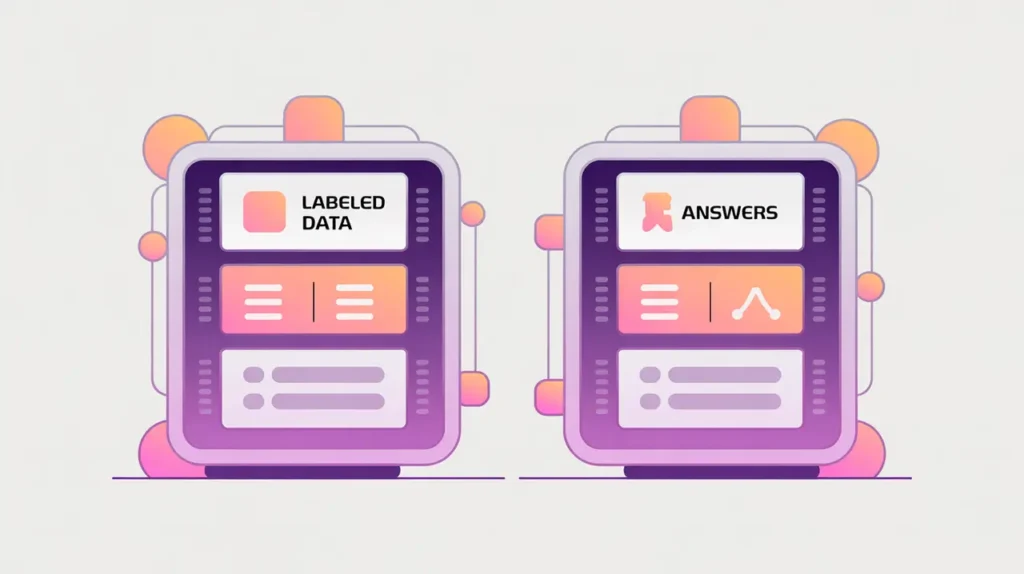
Unsupervised Learning refers to training algorithms on data without predefined labels or categories. Instead of predicting specific outcomes, the system looks for underlying structures such as clusters, associations, or patterns. Early work in statistics and information theory laid the foundation for techniques like clustering and dimensionality reduction, which are now core to this approach.
It differs from Supervised Learning, which requires labeled training data, and from Reinforcement Learning, which relies on feedback from an environment. Unsupervised methods are particularly useful when labeled data is expensive or impractical to obtain. Examples include grouping customers with similar purchasing behavior, compressing large datasets into smaller representations, or detecting anomalies that signal unusual activity.
How this Works in Practice
In practice, Unsupervised Learning works through algorithms such as k-means clustering, hierarchical clustering, and principal component analysis. These techniques group data points based on similarity or reduce the number of features while preserving essential structure. More advanced methods, like autoencoders and generative models, learn compressed representations that can reconstruct or generate new data.
The strength of Unsupervised Learning lies in its ability to surface patterns without prior human instruction. However, interpretation remains a challenge. Clusters or groupings discovered by the algorithm may not always correspond to meaningful categories in the real world. Success therefore depends on domain expertise to interpret the results and connect them to actionable insights. This interplay between automated discovery and human judgment is central to the effective use of Unsupervised Learning.
Implications for Social Innovators
In development contexts, Unsupervised Learning is especially valuable for exploration and discovery. Humanitarian agencies use clustering to analyze population movement data, identifying new settlements or displacement patterns without prior labeling. Public health programs apply anomaly detection to disease surveillance, spotting unusual spikes in symptoms that could indicate an emerging outbreak.
In agriculture, unsupervised techniques group crop images by disease type, helping researchers build more focused labeled datasets for later supervised training. In education, dimensionality reduction helps uncover learning patterns across student populations, guiding curriculum adjustments. These applications demonstrate that Unsupervised Learning can be a powerful first step in data-rich but resource-limited environments. It enables mission-driven organizations to detect signals in noise, prioritize areas of focus, and prepare the ground for more advanced predictive systems.